赛尔原创 基于序列到序列模型的句子级复述生成
宁丹丹
文章编号: 2095-2163(2018)03-0061-04中图分类号: 文献标志码: A
摘要: 关键词: (School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: Paraphrase is to change a sentence into another expression, meaning the same as before. Paraphrase is widely used in Natural Language Processing, for example, it is used in information retrieval, automatic abstracting, information extraction, sentence translation and so on. This paper focuses on the generation of sentence level paraphrase. In the research, first try the basic seq2seq model for sentence paraphrasing, then use bidirectional LSTM in encoder stage and join the attention mechanism, by comparing the generation results of sentences,demonstrate that the model with attention is better. In addition, further propose the copy mechanism and the coverage mechanism to improve the model. Among them, introduce the copy mechanism to solve special condition when names and places are present in original sentence. Under this condition, design to realize that the model can copy words without change. Experimental results show that the copy mechanism can improve the situation and generate better sentences. Finally, to address the common repetition problem of seq2seq, coverage mechanism is added on the basis of copy mechanism, which effectively improves this problem in sentences generation. And BLEU is used to evaluate the model results.
Key words:
作者簡介:
通讯作者: 收稿日期: 引言
复述(Paraphrase)是自然语言中普遍存在的一种现象,体现了自然语言的多样性。随着深度学习的发展以及自然语言处理各项技术的提高,对复述技术的需求也日趋强烈,因此,各大研究机构及高校等对复述任务的研究也越来越关注。复述研究的对象主要是有关短语或者句子的同义现象。现在已在信息检索、自动问答、信息抽取、自动文摘和机器翻译等方面应用广泛。在复述的研究前期,研究主要利用句子中词语之间的关系,句子的依存句法关系等进行复述生成,随着深度学习的发展,很多研究机构将深度学习技术应用到复述生成的任务中,并且具有显著的效果。本文采用序列到序列模型的方法,对句子级复述进行生成,在基本seq2seq模型上尝试3种改进方法,分别是双向LSTM 注意力机制的改进方法、加入复制(copy)以及加入 (coverage)机制的方法。其中,复制机制主要解决句子中词频比较低的词语的生成,例如在句子中会存在人名、地名等词频较低的词,在复述过程中,目标设定在生成的句子将这些名称进行复制,不进行改变,因此即有针对性地提出了复制机制。另外,seq2seq模型存在重复这一共性问题,本文采用覆盖机制对这一现象进行改进。经过如上3种改进方法,句子生成结果则获得了明显改进。
1基于序列到序列的句子级复述生成模型
在国内,句子级复述生成的研究也主要围绕seq2seq模型进行改进。2016年,Gu等人\[1\]提出CopyNet方法,在Attention-based Encoder-Decoder模型的基础上引入了一些改进,在decoder过程中,词的概率由generate-mode和copy-mode共同决定,其中后者表示该词来自原句。例如,在生成对话的过程中,就可以将人名这样的特殊词汇拷贝到回复句中。Cao等人\[2\]在句子级复述生成中借鉴CopyNet方法,提出了基于copy机制的复述生成模型,将该模型应用到文本简化、摘要生成等任务上,取得了较好的结果。相比Gu等人提出的CopyNet模型,该模型的优势是简单、易懂。国外研究人员在句子级复述任务上也开展了很多的研究工作,Prakash\[3\]等人在2016年提出了Stacked Residual LSTM networks用于复述生成问题上,通过利用基本seq2seq 的encoder-decoder模型,采用多层结构,在层与层之间加入残差来改善多层网络存在的梯度消失问题。Hasan\[4\]等人提出Neural Clinical Paraphrase Generation方法,用于临床医学术语等的复述问题上,目的是用通俗易懂的词代替一些专业医学术语,让患者更加容易理解,并且采用attention-based Bi-direction RNN的端到端结构进行复述生成,得到了较好的结果。另外,2017年,See\[5\]等人提出一种基于seq2seq模型的改进方法——Pointer-Generator Networks,并将其利用到文本摘要生成的任务当中,展现了较好的效果优势,其中seq2seq+Attention模型作为baseline,在此基础上加入Pointer-Gen机制,即加入一个参数,该参数决定当前词进行生成还是进行复制,随后在Pointer-Gen基础上加入覆盖机制,改善生成过程中出现的重复问题。
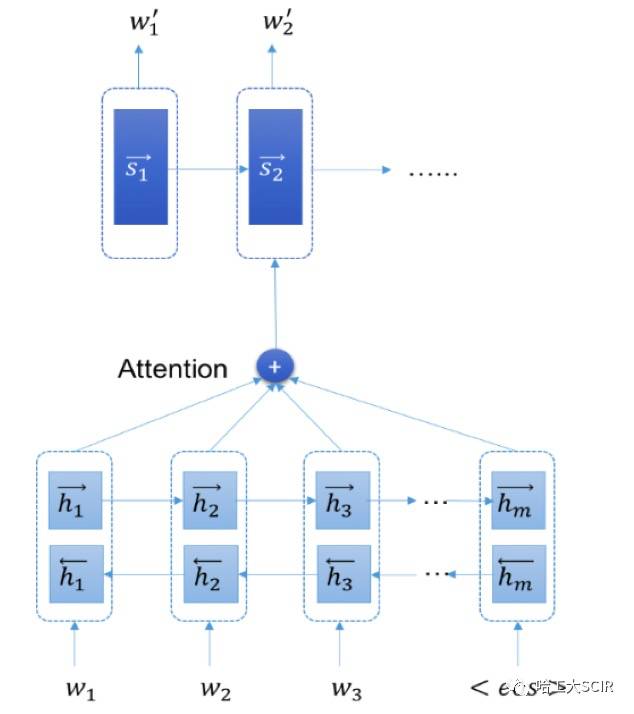
在本文中,在研究尝试了3种序列到序列模型的改进方法进行句子级复述生成,首先在基本seq2seq模型上加入注意力机制,在encoder阶段采用双向LSTM模型,用于提高seq2seq模型效果,模型结构设计如图1所示。
上述模型也存在一定的问题,当原句长度较长时,生成句子结果也并未呈现良好实效,当原句中存在一些人名、地名等词频较低和不在词表中存在的词时,期望的结果是生成的句子中也存在这些词,但是基本seq2seq模型和加入注意力机制的模型对这一问题没有提供特别的处理,导致生成的句子中人名、地名的特殊词语生成结果不好。所以,关于这一问题本文提出复制的思想,在注意力机制的模型上进行改进,一定程度上解决像人名、地名等OOV(out of vocabulary)的词语的生成情况。另一方面,seq2seq模型和加入注意力机制的模型生成的句子存在重复的问题,这个问题是seq2seq模型的一个通病。生成的句子越长,重复问题越明显,针对这一问题,本文提出覆盖机制来对这一问题进行改善,模型结构如图2所示。
2语料获取及处理
目前自然语言处理研究中,没有大规模现成的复述语料资源,需要采取一定的方法获取复述语料。例如英文词语级复述资源用WordNet\[6\]、MindNet\[7\]等获取,中文可以采用同义词词林、知网等。2001年,Barzilay\[8\]提出了一种基于外文翻译获取句子级复述语料库的方法。Shinyama\[9\]等人提出了利用同一个新闻事件的不同描述来获取复述语料,因而假定若2个句子中共同包含的命名实体超过一定的数量,那么这2个句子可以组成一个复述实例。
本课题借鉴前人Barzilay\[8\]及哈尔滨工业大学李维刚\[10\]等人的方法,从单语平行语料库中,也就是外文名著的不同译本获取复述实例。由于待处理的平行译文文本大多数是从网络上得到的 ,这些文本具有很多不规范的特征,例如这些文本一般是篇章对齐的,其中的段落没有严格对齐,并且在翻译时,为了保证翻译后的语句通顺,源语言的一句话可能被翻译成多句话。基于以上问题,首先需要将文本整合为一篇文章消除段落界限,利用二分图最优匹配的过程,对句子进行对齐,获取复述实例。
本文研究利用《百年孤独》和《呼啸山庄》两部外文名著的不同翻译版本获取复述语料,语料规模为:10 159句对。对抽取出的复述句对再次进行过滤处理,过滤规则是相对应的2句长度差超过一定的值则将该句对进行过滤,过滤处理后的语料规模为8 022句。
3评价指标与实验结果
3.1评价指标
本文采用机器翻译的一种评价方式——BLEU值对句子级复述生成的结果进行评价。该评价方式最先由IBM\[11\]在2002年提出,在机器翻译任务中,该评价方式的主要思想是若由模型翻译得到的句子越接近人工翻译的结果,则证明该模型效果越好,那么定义模型翻译得到的句子与人工翻译得到句子之间的相似度成为BLEU评价的核心内容。
首先,BLEU评价需要参考译文,对于本文句子级复述生成任务,这里的“参考译文”为复述后的句子。BLEU值通过比较并统计模型生成句子和复述句中共现的n-gram个数,最后把匹配到的n-gram的数目除以模型生成句子中词语的数目,得到评测结果。之后BLEU做了修正,首先计算出n-gram在一个句子中最大可能出现的次数,然后跟“参考译文”中n-gram出现的次数作比较,取两者之间最小值作为n-gram的最终匹配个数。首先,研究定义模型生成的句子为ci,“参考译文”即复述句表示为Si={si1, si2, …, sim}∈S,计算过程如下。
首先,计算句对中语料库层面上的重合精度CPnC,S:
CPnC,S=∑i∑kmin (hkci, maxj∈mhk(sij))∑i∑khk(ci) (1)
其中,wk表示第k組可能的n-grams,式(1)中hkci表示wk在模型生成句ci中出现的次数,hk(sij)表示wk在“参考译文”sij中出现的次数。
可以看出CPnC,S是个精确度度量,在语句较短时表现更好,所以BLEU加入惩罚因子BP。这里给出数学公式如下:bC,S=1 iflc>ls
e1-lslciflc
4结束语
本文主要提出了3种基于序列到序列模型的改进方法应用到句子级复述生成任务中,首先研究尝试了基本seq2seq模型用于句子复述,并尝试在encoder阶段采用双向LSTM,而后在双向LSTM基础上加入注意力机制,比较句子生成结果,可以得出加入注意力机制的模型生成结果效果要好。接着本课题提出复制机制和覆盖机制对模型进行改进,其中复制机制旨在解决原句中出现人名、地名等特殊词汇的情况,这样情况下将致力于模型可以对词进行复制,不进行改变,实验结果证明,复制机制对这一情况有所改善,句子生成效果较好,此外,针对seq2seq普遍存在的重复问题,研究还在复制机制的基础上加入覆盖机制,有效改善了生成句子的重复问题。
参考文献
[1] GU Jiatao, LU Zhengdong, LI Hang, et al. Incorporating copying mechanism in sequencetosequence learning[J]. arXiv preprint arXiv:1603.06393, 2016.
[2] CAO Ziqiang, LUO Chuwei, LI Wenjie, et al. Joint copying and restricted generation for paraphrase[J]. arXiv preprint arXiv:1611.09235, 2016.
[3] PRAKASH A, HASAN S A, LEE K, et al. Neural paraphrase generation with stacked residual LSTM networks[J]. arXiv preprint arXiv:1610.03098,2016.
[4] HASAN S A, LIU B, LIU J, et al. Neural clinical paraphrase generation with attention[C]//Proceedings of the Clinical Natural Language Processing Workshop. Osaka, Japan:[s.n.], 2016: 42-53.
[5] SEE A, LIU P J, MANNING C D. Get to the point: Summarization with pointergenerator networks[J]. arXiv preprint arXiv:1704.04368, 2017.
[6] MILLER G A, BECKWITH R, FELLBAUM C, et al. Introduction to wordnet: An online lexical database[J]. International Journal of Lexicography, 1990,3(4): 235-244.
[7] RICHARDSON S D, DOLAN W B, WANDERWENDE L. Mindnet: Acquiring and structuring semantic information from text[C]//COLING '98 Proceedings of the 17th international conference on Computational linguistics.Montreal, Quebec, Canada:ACM, 1998:1098-1102 .
[8] BARZILAY R, MCKEOWN K R. Extracting paraphrases from a parallel corpus[C]//ACL '01 Proceedings of the 39th Annual Meeting on Association for Computational Linguistics. Toulouse, France:ACM, 2001:50-57.
[9] SHINYAMA Y, SEKINE S, SUDO K. Automatic paraphrase acquisition from news articles[C]//HLT '02 Proceedings of the second international conference on Human Language Technology Research. San Diego, California:ACM, 2002:313-318 .
[10]李維刚. 中文复述实例与复述模板抽取技术研究[D]. 哈尔滨: 哈尔滨工业大学, 2008.
[11]PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation[C]// ACL '02 Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, Pennsylvania: ACM,2002:311-318.








